
„Historisch gewachsen“ diesen Begriff kennt so gut wie jeder, der mit Datenplattformen arbeitet. Meist werden damit Strukturen und Artefakte beschrieben, die keiner mehr versteht und die man lieber nicht anfasst. Manchmal handelt es sich um provisorische Lösungen, die nie abgelöst wurden. In anderen Fällen wuchs die Komplexität durch schrittweise Erweiterungen und Anpassungen initiiert durch sich wandelnde Anforderungen.
Gewachsenen Datenstrukturen und Datenmodellen gemein ist, dass sie meist durch eine hohe Komplexität und undurchsichtige Strukturen geprägt sind. Gerade in Self-Service Umgebungen mit vielen verschiedenen Akteuren fehlt oft eine Gesamtübersicht über Abhängigkeiten. Die hohe Komplexität verursacht verschiedene Probleme. Änderungen sind schwierig durchzuführen und fehleranfällig. Die Performance leidet. Fehleranalyse- und behebung nehmen viel Zeit in Anspruch. Neuentwicklungen sind entsprechend gelähmt.
Damit stellt sich die Frage wie es besser geht. Wie geht Wachstum nachhaltig? Wie skaliert man eine Datenlandschaft ohne die Komplexität zu skalieren? Wie geht man mit bestehenden, gewachsenen Artefakten um?
Diese Fragen wollen wir im Folgenden beantworten. In diesem Artikel konzentrieren wir uns dabei auf Self-Service-Umgebungen in Power BI. Zunächst gehen wir auf Ursachensuche und zeigen auf, wie Datenmodelle wachsen können, ohne dabei zu komplex zu werden.
Im zweiten Teil des Artikels beschäftigen wir uns mit Strategien, wie das Wachstum skaliert wird und dabei nachhaltig bleibt.
Ursachensuche: Warum nimmt die Qualität ab?
Um es besser zu machen, müssen wir zunächst einmal das Problem verstehen: Warum nimmt die Qualität von Datenprodukten mit der Zeit ab?
Die Datendemokratisierung in Unternehmen bringt die Anforderung nach schnellen Änderungen und Erweiterungen von Power BI Datenmodellen mit sich.. Bei neuen Anforderung oder Änderungen haben Entwickler grundsätzlich drei Handlungsmöglichkeiten um die Anforderung in das Datenmodell zu integrieren:
-
Man kann das bestehende Dataset verändern, also neue Artefakte hinzufügen aber auch bestehende Tabellen und Beziehungen verändern. Dies birgt das Risiko, dass abhängige Artefakte (z.B. Berichte) ebenfalls angepasst werden müssen.
-
Man kann das bestehende Dataset erweitern. Etwa durch zusätzliche Measures, Tabellen oder Spalten, aber ohne Änderungen an bestehenden Artefakten vorzunehmen. Das hat meistens keine Auswirkungen auf bestehende, abgeleitete Artefakte.
-
Man kann eine Kopie des Datasets anpassen und daneben setzen. Das führt auf lange Sicht zu vielen Kopien und ist in der Wartung sehr aufwendig.
In Einzelfällen können die erste und die dritte Option sinnvoll sein. In den allermeisten Fällen wird aufgrund von Ressourcenknappheit und Zeitdruck die zweite Option gewählt. Das heißt allerdings, dass die Datasets mit der Zeit immer weiter wachsen und immer komplexer werden.
Komplexere, größere Datasets sind problematisch, da sie meist zu folgenden Problemen führen:
-
Steigende Entwicklungsdauer
-
Sinkende Performance
-
Anwender(un)freundlichkeit
-
Erhöhte Belastung der IT
-
Sinkende Motivation der Nutzer
Diese Probleme treten insbesondere dann auf, wenn die Änderungen nur mit aktuellen Anforderungen abgeglichen werden und die Gesamtkomplexität dabei aus den Augen gerät.
Wie können Datenmodelle nachhaltig wachsen?
Mit der Erkenntnis, dass Datenmodelle mit der Zeit wachsen werden, müssen wir uns folgende Fragen stellen : Wie können Datenmodelle nachhaltig wachsen? Welche Best Practices und Vorgehensweisen ermöglichen große Datenmodelle ohne überbordende Komplexität?
In diesen Artikel möchten wir vier Empfehlungen geben:
-
Verwendung vom themenspezifischen, zentralen Datenmodellen
-
Datenmodell als Data Mart (Star-Schema) modellieren
-
Durch Entwicklungsstandards die Erweiterung standardisieren und erleichtern
-
Durch klare Ansprechpartner Probleme frühzeitig erkennen
Verwendung vom themenspezifischen, zentralen Datenmodellen
Häufig werden in Unternehmen mit hohem Self-Service Anteil für fast alle Berichte eigene Datenmodelle erstellt. Dies sorgt für einen hohen redundanten Entwicklungsaufwand und eine geringe Qualität in der Datenmodellierung.
Die Verwendung zentraler, themenspezifischer Datenmodelle, auf denen unterschiedliche Anwender mehrere Berichte aufbauen können, ermöglicht es Entwicklern mehr Zeit in die Konzeption und Entwicklung dieser Datenmodelle zu investieren. Die Fehlerquote sinkt und die Perfomance steigt.
Unternehmen sollten für die häufigsten Auswertungsbereiche z.B. Kostendaten im Controlling, zentrale Datenmodelle erstellen, auf dem die Anwender ihre Berichte erstellen können.
Ein zentrales Datenmodell enthält in der Regel neben den Tabellen und Beziehungen auch die wichtigsten Kennzahlen und KPIs. Außerdem sollte ein zentrales Modell die folgenden Eigenschaften und Funktionen besitzen:
-
Die Korrektheit der Daten und der fachlichen Inhalte wird regelmäßig validiert.
-
Die Aktualität und die Vollständigkeit der Daten werden durch eine automatisierte Aktualisierung gewährleistet.
-
Durch eine RLS können Anwender mit unterschiedlichen Berechtigungen dasselbe Modell verwenden.
-
Das Dataset ist dokumentiert.
-
Jedes Modell besitzt einen fachlichen und einen technischen Verantwortlichen.
-
Eine Kennzeichnung weist zentrale Modelle aus.
Merke: Investitionen in die Qualität der Datenmodellierung von zentralen Datenmodellen zahlen sich später durch eine einfachere Entwicklung von Berichten mehrfach aus.
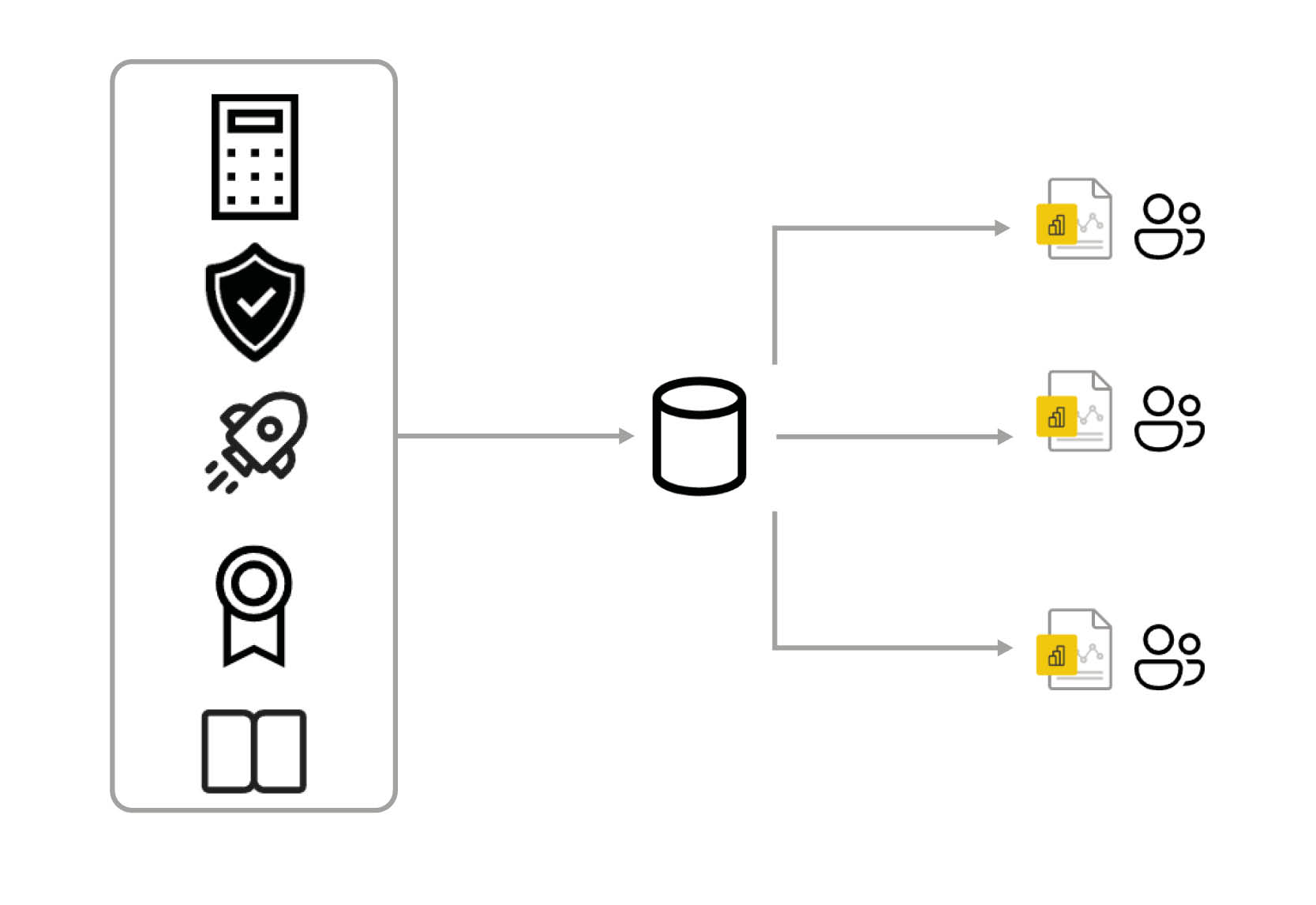
Erweiterung von Datenmodellen muss von Beginn an mitdenken
Eine zentrale Erkenntnis der Problemanalyse ist, dass Datenmodelle mit der Zeit wachsen werden. Daher sollten wir ein Modellierungsverfahren wählen, welches auf Wachstum ausgelegt ist.
Die Verwendung von Data Marts in Form von eines Star-Schemas ist empfehlenswert. Sie vereinigt die Anforderungen nach Benutzerfreundlichkeit, Einhaltung von Power BI Best Practises und der einfachen Erweiterbarkeit am besten.
Ein Data Mart besteht aus Fakten und Dimensionen. Faktentabellen enthalten numerische Kennzahlen, die den Kern einer Analyse oder Berichterstattung bilden. Jeder Analysebericht erhält eine eigene Faktentabelle. Beispiele für Faktentabellen sind Ist-Kosten, Schaden oder Abrechnungen. Dimensionen sind die Beschreibungselemente, mit denen die Fakten in einem Data Mart kontextualisiert und analysiert werden können. Beispiele hierfür sind das Abrechnungsdatum, Schadenart oder Kostenstellen.
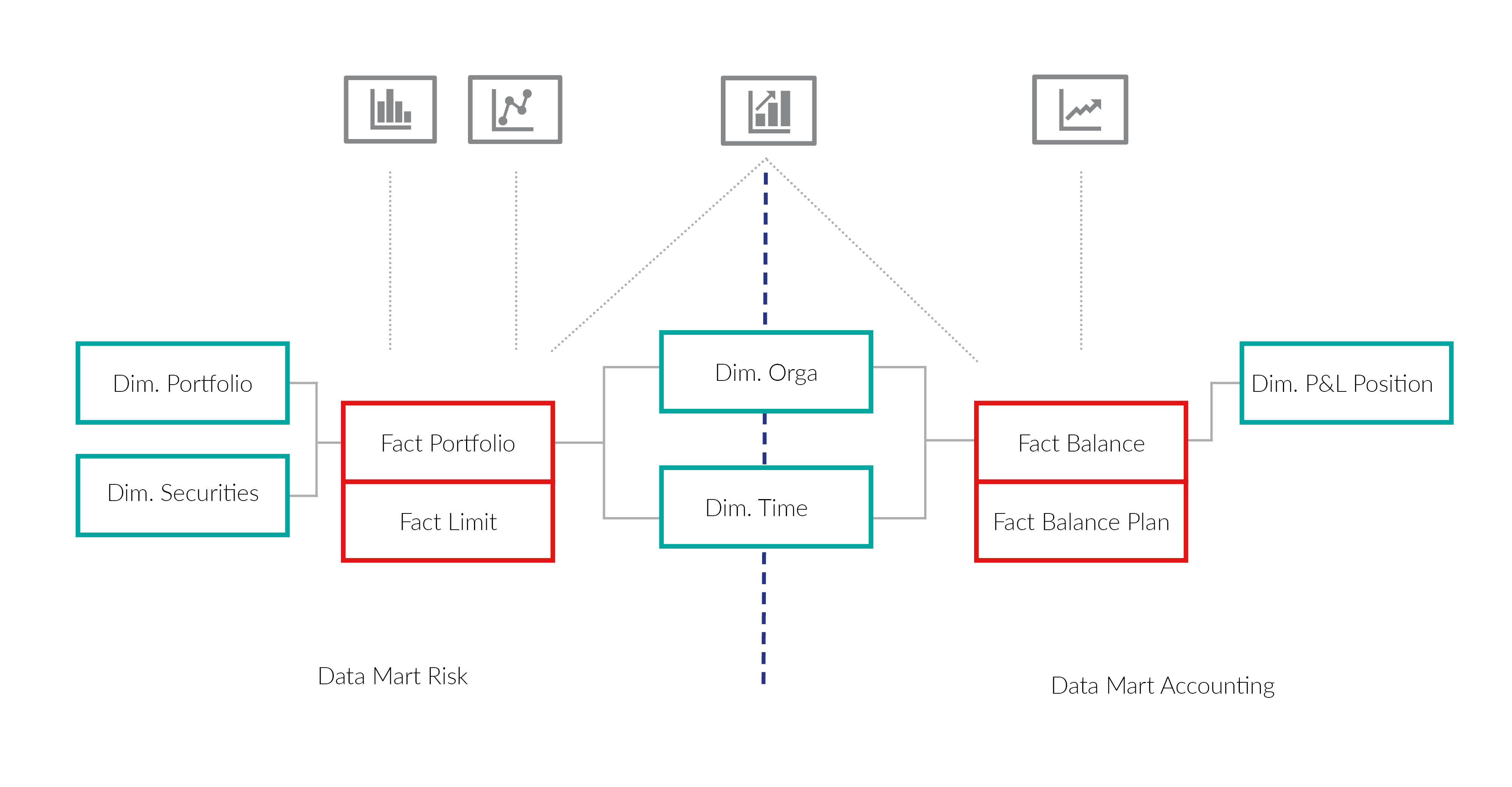
Die Fakten haben nur Beziehungen zu den Dimensionstabellen. Fakten haben keine direkten Beziehungen untereinander. Es ist empfehlenswert die Beziehungen auf technischen Schlüssen anzulegen, wenn es in der Zukunft zu einer Änderung der Geschäftslogik kommt, dann müssen nur die technischen Schlüssel neu berechnet werden und nicht das gesamte Modell verändert werden.
Erweiterbarkeit:
Bei einer Erweiterung des Modells, kann entweder eine neue Fakten- bzw. Dimensionstabelle angelegt oder eine bestehende Tabelle um zusätzliche Spalten erweitert werden. In allen Fällen können die alten Strukturen und Berichte unverändert bleiben. Durch eine solche Erweiterung werden Abfragen, welche nicht von der Anpassung direkt betroffen sind, nicht komplexer.
Natürlich gibt es auch im Sternschema Änderungen, die Anpassungen in abhängigen Berichten nach sich ziehen. Dies sind zum Beispiel Feld-Umbenennungen und Löschen von Feldern und Tabellen. Diese Änderungen sollten so selten wie möglich notwendig sein. Eine Möglichkeit Feldumbenennungen abzufangen, ist die Verwendung von Views zum Abrufen der Daten aus der Datenbank. Diese Fälle führen jedoch in allen Modellierungsarten zu Anpassungen in den Berichten.
Learnings
Kurz gesagt, liegt das Grundproblem wachsender Datenlandschaften darin, dass bei der schrittweisen Erweiterung und Anpassung an neue Anforderungen, die Skalierbarkeit und Wartbarkeit der Gesamtlösung aus dem Blick gerät. Dies führt zu immer komplexeren Modellen und bremst Neuentwicklung.
Durch die Nutzung zentraler semantischer Modelle kann sich auf die Optimierung der wichtigsten Modelle konzentriert werden. Die Wahl des Modellierungsschemas muss zukünftige Änderungsanforderungen berücksichtigen. Im Reporting hat sich hier das Sternschema bewährt. Es lässt sich gut erweitern, ist einfach zu verstehen und bietet gute Performance.
Kommende Woche zeigen wir Strategien, wie das Wachstum skaliert und dabei nachhaltig bleibt. Dabei werden wir mithilfe von Skripting automatisch Datenmodelle erweitern und aufzeigen, wie Unternehmen vorgehen können wenn Ihr Datenmodell bereits zu komplex geworden sind.
Haben Sie Fragen oder Anmerkungen? Gerne stehen Ihnen unsere Kolleg:innen Miklas Horstmann und Vera Elliger für einen Austauch zu Verfügung. Hier geht es zu unserem Kontaktformular.