
Power BI ist ein mächtiges Analysetool. Es hilft vielen Unternehmen wertvoller Erkenntnisse aus ihren Daten zu gewinnen. Die Grundlage für Berichte und Dashboard sind Power BI Datasets. In ihnen findet die Power-BI-interne Datenmodellierung statt. Die manuelle Erstellung solcher Datasets ist ein zeitaufwändiger und fehleranfälliger Prozess. Deshalb haben wir eine Automationslösung entwickelt, die wir Ihnen in diesem Blogpost vorstellen werden.
Mit unserer Power BI Dataset Automation sinken die Entwicklungskosten pro Dataset während die Entwicklungsgeschwindigkeit erhöht wird. Unsere Lösung kann sowohl für die initiale Erstellung von Datasets als auch für spätere Änderungen verwendet werden. Das Zauberwort unserer Automatisierung heißt „Metadaten“. Die Metadaten sind der Input unserer Lösung und definieren die Ausgestaltung der Datasets.
Status Quo: Wie sieht die Erstellung eines PowerBI Reports heute aus?
Berichte und Auswertungen sind meist das letzte Glied in der Kette der Datenverarbeitung. Gerade in größeren DWH-Architekturen finden die Datenaufbereitung und Datenmodellierung bereits in der Datenbank selbst statt.
Nachdem diese aufwendige Arbeit durch die Data Engineers erledigt worden ist, können die Data Analysten mit ihrer Arbeit in PowerBI beginnen. Für die Erstellung der Reports müssen die Daten nur noch aus der Reporting Schicht der Datenbank abgerufen werden. Hier beginnt eins der leidigsten Themen im Alltag eines Data Analysten. Denn trotz der vorherigen Aufbereitung in der Datenbank müssen einige repetitive Modellierungsschritte in Power BI durchgeführt werden. Hierzu gehören:
-
Auswählen der einzuladenden Tabellen und Spalten
-
Festlegen der Datentypen aller Spalten
-
Festlegen des automatischen Aggregationsverhalten der numerischen Spalten
-
Anlegen der Beziehungen zwischen den Tabellen
-
Anlegen von Measuren für typische Kennzahlen
-
Anlegen von Sicherheit auf Zeileneben (RLS)
Gerade in großen und komplexen Datenmodellen mit vielen Tabellen und Spalten, kann diese manuelle Vorgehensweise nicht nur zeitraubend, sondern auch fehleranfällig sein. Weiterhin hat die manuelle Variante weniger neue Use Cases zur Folge, es entstehen hohe Kosten und eine schlechte Wartbarkeit sowie trägt zur Demotivation der Mitarbeiter bei. Es stellt sich die Frage: Kann diese mühsame Arbeit nicht effizienter erledigt werden? Die Antwort ist "Ja": Mit unserer Power BI Dataset Automation können wir die Datenmodelle anhand von Metadaten automatisiert erstellen. Im Folgenden beschreiben wir die Details unserer Lösung.
Das PBIP Format: Der Startpunkt für unsere Automation
Das gezippte PBIX-Format hat der Power BI Community schon lange Kopfzerbrechen bereitet. Kollaboratives Arbeiten, Versionskontrolle und Änderungsnachverfolgung in Power BI Datasets wurden damit nicht unterstützt. Mit der Git-Anbindung für Power BI Workspaces und der damit verbundenen Einführung des neuen PBIP-Formats im Mai 2023 hat sich das verändert. Das Power BI Projektdatei-Format PBIP speichert Reports und Datasets in mehreren für Menschen lesbaren Textdateien ab. Diese Änderung ermöglicht nicht nur Änderungsnachverfolgung und Versionskontrolle, sondern ebnet auch den Weg für die automatisierte Generation von PBI Artefakten.
Wie funktioniert die PBIP-Datei?
Beim Speichern als PBIP-Projekt-Datei werden zwei Ordner mit Textdateien angelegt. Analog zu den Artefakten im PowerBI Service gibt es einen Ordner für den Bericht und einen Ordner für das Dataset.

Die interessante Logik für das Dataset steckt in der model.bim-Datei. Hier wird das Power BI Model in TMSL (Tabular Model Scripting Language) definiert.
Unsere Lösung
Genau an der model.bim-Datei setzt unsere Automatisierungslösung an, um Power BI Datasets für Datenmodelle aus der Datenbank zu generieren. Um das Power BI Model in TMSL schreiben zu könne, müssen die Metadaten des Modells (sprich die einzuladenden Tabellen, ihre Spaltennamen und Datentypen, die Beziehungen der Tabellen untereinander etc.) bekannt sein. Aus diesen wird die Beschreibung der Objekte in TMSL generiert.
Unserer Lösung ist es dabei egal, woher diese Metadaten kommen. In vielen Umgebungen liegen die Metadaten der Reportingschicht der Datenbank bereits vor. Ist dies nicht der Fall, haben wir im Zuge unseres Data Management Automation and Processing Frameworks Lösungen entwickelt, Metadaten automatisiert auszulesen. Das Wichtige ist, dass die Metadaten in der erwarteten Struktur im JSON-Format im Metadaten-Repository abgelegt werden. Die Dataset-Bearbeitung findet über die Modellierung dieser Metadaten statt. Der eigentliche Erstellungsprozess läuft dann von allein. Wie das technisch funktioniert, erklären wir im nächsten Abschnitt.
Technische Funktionsweise unserer Lösung - ein Blick unter die Motorhaube
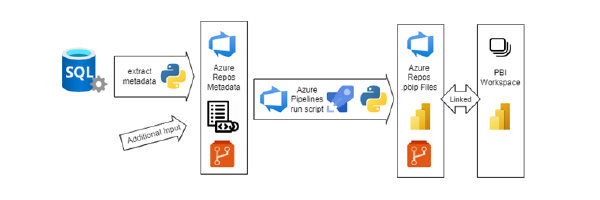
Unsere PBI Dataset Automation besteht aus drei Azure Repositories:
-
Das Metadaten-Repository: Hier werden die Metadaten der Power-BI Datasets abgelegt. Diese können maschinell erzeugt und mit manuellem Input ergänzt werden. Änderungen im Metadaten-Repository triggern die Azure Pipeline.
-
Das Code-Repository ist das Herz der Automatisierungslösung. Hier liegt der Python-Code, der die Metadaten einliest, Datentransformationen durchführt und die PBIP-Dateien schreibt. Außerdem liegt hier der YAML-Code für die Pipeline, welche den Python-Code ausführt und die Änderungen commitet.
-
Das PBI-Files-Repository ist mit einem PBI-Service verknüpft. Hierhin werden die PBIP-Dateien von der Pipeline geschrieben. Änderungen werden automatisch vom PBI-Service erkannt und als Updates angezeigt.
Der Python-Code besteht aus verschiedenen Submodulen. Der Metadaten-Service liest die Metadaten ein und macht diese zugänglich. Ein Datentyp-Transformer wandelt beliebige Datenformate in M- oder TMSL-Datentypen um. Der Power-BI-Modell-Builder erstellt Power-BI-Entitäten (beispielsweise Spalten oder Tabellen) und setzt diese zu einem TMSL-Modell zusammen
In unserer Demo-Version der PBI-Dataset-Automation können wir bereits ein Power BI Modell mit ausgewählten Tabellen und Spalten erzeugen. Die Datentypen und die automatische Aggregation werden festgelegt und Beziehungen zwischen den Tabellen erstellt.
Grundsätzlich ist die Erzeugung aller Eigenschaften, die im TMSL-Modell definiert werden können, denkbar – es braucht nur die geeigneten Metadaten. Weitere Eigenschaften, die aus Metadaten generiert werden könnten sind beispielsweise Measure-Definitionen, Tabellenpartitionen und das Anlegen von Sicherheit auf Zeilenebene (RLS).
Mit Automation Kosten und Zeit sparen
Mit unserer Power BI Dataset Automation können Power BI Dataset auf Basis von Metadaten erstellt werden. Das mühsame Modellieren in Power BI Desktop entfällt. Insbesondere in Datenlandschaften mit zahlreichen Datamarts sowie vielen Tabellen und Spalten wird die Automatisierung der Dataset-Erstellung den größten Nutzen bieten. Neben der Kosten- und Zeitersparnis durch geringere Entwicklungskosten, wird die Entwicklung deutlich schneller.
Die Datasets sind innerhalb weniger Minuten erstellt. Das eröffnet ganz neue Möglichkeiten. In Verbindung mit einem Metadaten-Scanner könnten Änderungen in der Datenbank automatisch in die Datasets übernommen werden. Außerdem eröffnet sich die Möglichkeit CI/CD Prozesse für Power BI Artefakte weiter zu beschleunigen. Die Power BI Dataset Automation kann hierbei auch in ein metadaten-gesteuertes Datenmanagement - wie wir es beispielsweise in unsere Data Management Automation Framework (Link) entwickeln – integriert werden. Mit dem Framework erfolgt die Entwicklung von Datenprozessen über die Modellierung der Metadaten.
Interessieren Sie sich für die Automatisierung ihrer Analytics Umgebung und haben Interesse an einem Austausch? Gerne stehen unsere ExpertInnen Vera Elliger und Miklas Horstmann für Gespräche zur Verfügung. Kontaktieren Sie uns gerne.