
Die Geschichte der Datenplattformen reicht zurück bis in die 1960er und 1970er Jahre, als erste Data Warehouse Systeme entwickelt wurden, um den wachsenden Bedarf an zentralisierten, strukturierten und leicht zugänglichen Datenbeständen zu decken. Data Warehouse Systeme waren die dominierende Datenarchitektur bis in die 2000er Jahre hinein, wobei sie Unternehmen dabei halfen, ihre strukturierten Daten effizient zu speichern, zu verwalten und zu analysieren. Mit dem Aufkommen des Internets und der explosionsartigen Zunahme an digitalen Daten stießen Data Warehouse Systeme jedoch an ihre Grenzen. Dies lag oft an der Vielfalt der Formate. Daten fallen in der Regel in drei Kategorien: strukturierte, unstrukturierte und semi-strukturierte Daten.
Strukturierte Daten sind quantitativ spezifiziert, technisch organisiert und typisiert, z. B. Namen, Geburtstage, Adressen, Sozialversicherungsnummern, Aktienkurse und geografische Lage in den Attributen einer Datenbanktabelle.
Unstrukturierte Daten sind eher qualitativ ausgedrückte Inhalte. Sie haben keinen technisch beschriebenen Aufbau und sind nicht leicht durchsuchbar, wie z. B. textuelle Online-Bewertungen, Videos, Fotos oder Audiodateien.
Semi-strukturierte Daten kombinieren Elemente der beiden anderen. Sie haben einen schwach definierten, technischen Aufbau, wie z. B. E-Mails, die Adressen für Absender/Empfänger haben, aber einen Textinhalt, der alles Mögliche enthalten kann.
Neben der Formatvielfalt und dem Datenvolumen ist oft auch die Veränderungsgeschwindigkeit der Data Warehouse Systeme ein beschränkender Faktor.
“If the rate of change on the outside exceeds the rate of change on the inside, the end is near.”
Jack Welch, ehemaliger CEO von General Electric.
Das bekannte Zitat von Jack Welch lässt sich wunderbar auf Datenplattformen übertragen. Wenn sich die Umgebung - d.h. in diesem Kontext die Datenquellen, die anzubindenden Systeme, die Technologien oder fachlichen Anforderungen der Nutzer - schneller ändern als die Module oder Datenprodukte der Datenplattform, dann sinkt unweigerlich die Akzeptanz der Plattform und sie degeneriert.
Data Warehouse
Ein Data Warehouse ist ein Speicher für große Mengen strukturierter Daten aus verschiedenen Datenquellen - wobei das Wort "strukturiert" die entscheidende Rolle spielt.
Die Daten in einem Data Warehouse werden zur zeitlichen Historisierung, Validierung, Integration, Sortierung, Zusammenfassung, Aggregation, Analyse, Berichterstattung oder Klassifizierung verarbeitet. Ein Data Warehouse ist hochgradig organisiert und für eine nachhaltige und sichere Aufbewahrung der Daten formatiert. Es wird eine schnelle Aufbereitung gewährleistet, dies bietet die Basis für eine klassische Berichtserstellung. Es ermöglicht einer Organisation den einfachen Zugriff auf relevante Daten und deren Analyse, um verwertbare Erkenntnisse zu gewinnen.
Bestandteile eines Data Warehouse
Um diese Erkenntnisse zu gewinnen, besteht ein Data Warehouse aus vier Kernkomponenten: einer zentralen Datenbank, Datenintegrationstools, Metadaten und Datenzugriffstools.
Zentrale Datenbank: Eine zentrale Datenbank ist das Rückgrat eines Data Warehouse und enthält Daten, die in Tabellen organisiert sind, in denen verwandte Objekte zusammengefasst sind.
Datenintegrations-Tools: Datenintegrationstools werden verwendet, um Daten aus verschiedenen Quellen zu extrahieren und sie so umzuwandeln, dass sie in das Data Warehouse passen bzw. den fachlichen Anforderungen zur Analyse genügen. Der traditionelle Ansatz, der hier verwendet wird, heißt Extrahieren, Transformieren und Laden (ETL), obwohl auch Extrahier-, Lade- und Transformierverfahren (ELT) populär geworden sind.
Metadaten: Metadaten sind Daten über Ihre Daten und werden verwendet, um Kontext und Organisation zu schaffen. Wenn zum Beispiel eine Fotodatei ein Datenpunkt ist, dann sind das Datum, der Standort und der Kameratyp Metadaten, die helfen, die Datei besser zu kontextualisieren und zu organisieren.
Werkzeuge für den Datenzugriff: Datenzugriffs-Tools wie Abfrage-Tools, Anwendungsentwicklungs-Tools, Data-Mining-Tools und Online-Analytical-Processing-Tools (OLAP) geben den Benutzern die Möglichkeit, mit den gespeicherten Daten im Data Warehouse zu interagieren.
Das klassische Data Warehouse kann seine Vorteile bei der Integration strukturierter Daten aus verschiedenen Datenquellen voll ausspielen.
Data Lake
Die 2010er Jahre brachten die Data Lake Ära, die als Reaktion auf die wachsenden Anforderungen an die Verarbeitung und Analyse von unstrukturierten und semi-strukturierten Daten entstanden. Data Lakes ermöglichten die Speicherung und Verarbeitung von Daten in ihrem ursprünglichen Format, wodurch Unternehmen in der Lage waren, Big Data und neue Datenquellen wie Social-Media-Daten, Sensordaten und Multimedia-Inhalte zu nutzen. Trotz ihrer Flexibilität und Skalierbarkeit hatten Data Lakes jedoch auch Schwächen, insbesondere im Hinblick auf Datenqualität, Historisierung, Data Governance und analytische Leistungsfähigkeit.
Unterschiede zum Data Warehouse
Während sowohl Data Lake als auch Data Warehouse Datenspeicher sind, besitzen sie unterschiedliche Eigenschaften und erfüllen unterschiedliche Zwecke.
Ein Data Warehouse verarbeitet und speichert in i.d.R. strukturierte Daten. Es eignet sich daher gut für Geschäftsberichterstattung und Analytik.
Der Hauptvorteil eines Data Warehouse liegt in seinem Schema-on-Write-Ansatz, bei dem die Daten strukturiert werden, bevor sie gespeichert werden. Dies gewährleistet eine effiziente Organisation der gespeicherten Daten. Dies erleichtert auch den Datenabrufprozess, was in Szenarien von Vorteil ist, in denen die Fragen und die Struktur der Daten im Voraus festgelegt sind.
Ein Hauptmerkmal eines Data Lakes ist sein Schema-on-Read-Ansatz, bei dem Daten erst dann strukturiert werden, wenn sie gelesen werden. Diese Eigenschaft bietet hohe Flexibilität bei der Aufnahme von Daten in verschiedenen Formaten. Ein Data Lake ist für die Integration von semi- oder unstrukturierten Daten ausgelegt und speichert diese in den meisten Fällen unverarbeitet. Dies vereinfacht maßgeblich die technische Umsetzung bei der Vielfalt der existierenden Datenformate und Liefersysteme. Diese Flexibilität macht einen Data Lake darüber hinaus zu einer ausgezeichneten Wahl für Datenexploration, Datenerkundung und maschinelles Lernen, bei denen Fragen nicht im Voraus vollständig bekannt sind. Data Lakes basieren auf kostengünstigem Objektspeicher und bieten Unternehmen eine einfache und skalierbare Speicherung.
Ein verbreitetes Problem bei Data Lakes besteht darin, dass sie als Speicher für praktisch alle Arten von Daten dienen. Eine Integration unterschiedlicher Datenformate mit dem Ziel, historisierbare Datensysteme zu schaffen, welche transaktionale Unterstützung im Sinne von ACID bieten, ist in reinen Data Lake Strukturen nicht nativ möglich. In der Folge sind Daten im Data Lake weniger organisiert, in nicht integrierten Datenstrukturen und -formaten, welche oft nicht katalogisiert sind und deren Änderungshistorien schwer nachvollzogen werden können.
Ein wesentlicher Teil heutiger Unternehmensdaten sind nicht-relationale Dateninhalte und eine Analyse dieser semi- und unstrukturierter Daten hat hohes Potenzial, daher wurde eine Lösung angestrebt, welche die Eigenschaften eines Data Warehouse Systems mit den Möglichkeiten eines Data Lakes verbindet.
Data Lakehouse
In den späten 2010er und frühen 2020er Jahren gewannen Data Lakehouse Systeme als nächste Evolutionsstufe der Datenplattformen an Bedeutung. Ein Data Lakehouse vereint die Vorteile von Data Warehouse und Data Lake Systemen, indem sie die Flexibilität und Skalierbarkeit von Data Lakes mit der Datenstruktur, Governance und Performance von Data Warehouse Systemen kombinieren. Strukturierte, semi-strukturierte und unstrukturierte Daten können mit Hilfe von ACID-Transactions und gleichzeitig hoher Qualität, Konsistenz und Sicherheit verarbeitet werden. Durch leistungsfähige Mechanismen zur Verarbeitung und Anfrage von polystrukturierten Daten, können in einem Data Lakehouse Datenanforderungen aus einem zentralen Knotenpunkt bedient werden.
Ein Data Lakehouse ist in der Lage, sowohl Rohdaten für KI-Lösungen als auch aufbereitete Daten für Data Analytics, Dashboards und Self-Service-Reporting bereitzustellen. Dadurch ermöglicht ein Data Lakehouse sowohl die Umsetzung analytischer Lösungen als auch die enge Integration von Analytics in operative Lösungen zur Automatisierung und Optimierung der Kernprozesse eines Unternehmens.
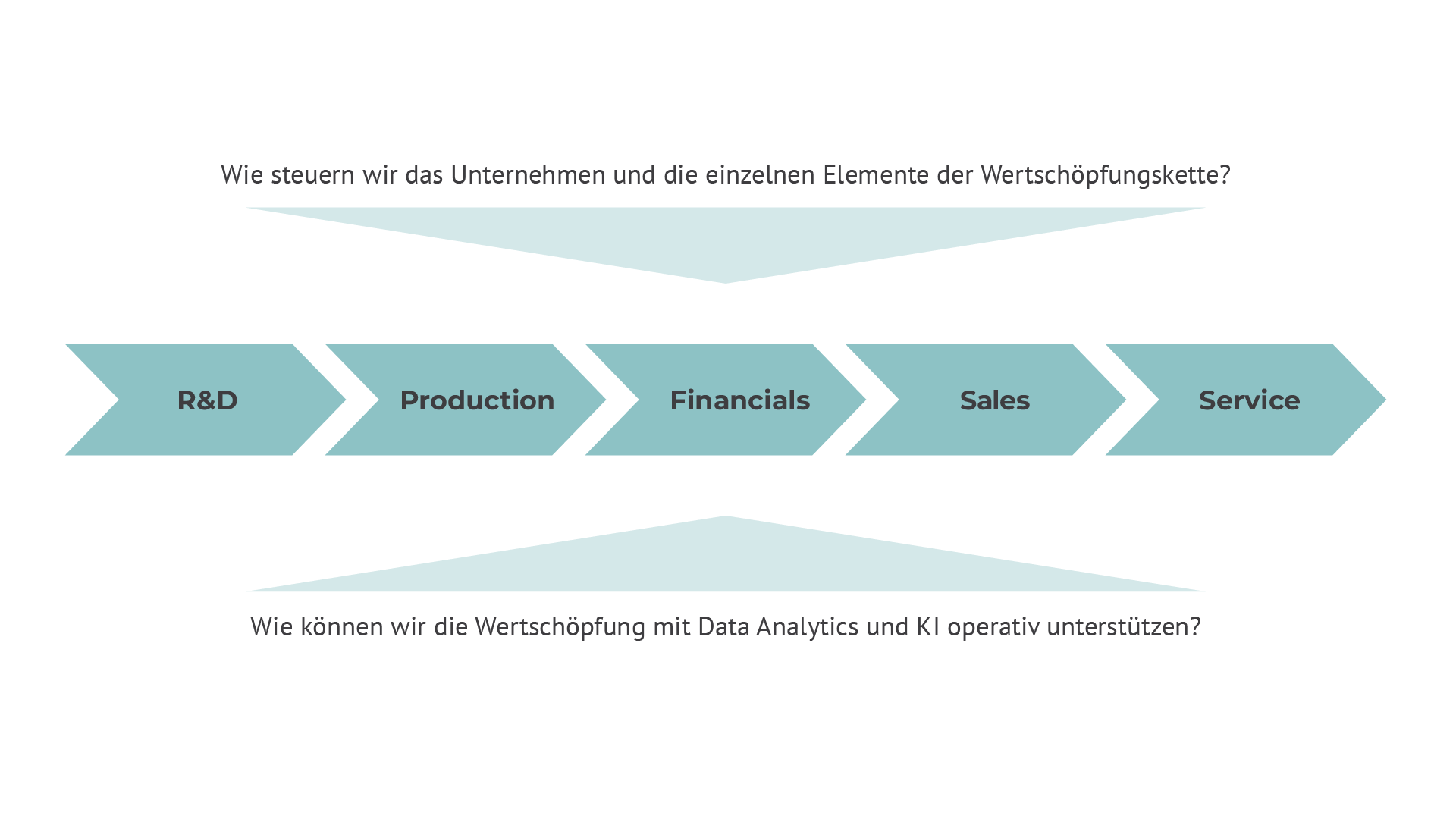
Bild: Das Data Lakehouse ermöglicht dispositive und operative Data Analytics entlang der Wertschöpfungskette
Eine Data Lakehouse Architektur ermöglicht es Unternehmen, sowohl strukturierte als auch unstrukturierte Daten effizient zu speichern und zu verarbeiten, während gleichzeitig ein hohes Maß an Datenqualität, Konsistenz und Sicherheit gewährleistet wird.
Eigenschaften eines Data Lakehouse
Flexibilität und Skalierbarkeit: Ein Data Lakehouse verarbeitet verschiedene Datenformate und -typen, da es die Flexibilität von Data Lakes beibehält. Das bedeutet, dass es sowohl strukturierte Daten als auch unstrukturierte oder semi-strukturierte Daten unterstützt. Diese Flexibilität ermöglicht es Unternehmen, Rohdaten aus verschiedenen Quellen für KI-Lösungen bereitzustellen, die in der Regel große Mengen an unstrukturierten Daten erfordern und gleichzeitig Self-Service Analytics zu ermöglichen.
Datenstruktur und Governance: Data Lakehouse Systeme integrieren die Struktur und Governance-Merkmale von Data Warehouse Systemen, um ein hohes Maß an Datenqualität, Konsistenz und Sicherheit zu gewährleisten. Das bedeutet, dass aufbereitete und strukturierte Daten effizient gespeichert und verwaltet werden können, was für Data Analytics, Dashboards und Self-Service-Reporting-Anwendungen entscheidend ist.
Message, Streaming und Batch: Data Lakehouse Systeme ermöglichen die Verarbeitung von Batch Prozessen, Streaming Daten und Message-orientierter Datenverarbeitung. Sie dienen damit als Basis sowohl für Neartime Dashboards als auch für klassisches Tages- oder Monatsreporting.
Cloud-Native Architektur: Data Lakehouse Systeme sind meist als cloud-native Lösungen konzipiert, die es Unternehmen ermöglichen, ihre Dateninfrastruktur einfach und kosteneffizient zu skalieren. Diese Cloud-Native Architektur fördert die Agilität und ermöglicht die gleichzeitige Unterstützung von KI-Lösungen und analytischen Anwendungen ohne Leistungseinbußen.
Ein Data Lakehouse bietet eine leistungsfähige und flexible Plattform, die in der Lage ist, sowohl Rohdaten für KI-Lösungen als auch aufbereitete Daten für Data Analytics, Dashboards und Self-Service-Reporting bereitzustellen. Dies ermöglicht Unternehmen, vielseitige Datenprodukte und Datenapplikationen zu entwickeln, um mehr datengetriebene Entscheidungen zu treffen.
Daten als Produkt
In Data Lakehouse Systemen können kostengünstig große Datenmengen verarbeitet und gespeichert werden. Dadurch kann Data Management technisch skalieren. Da die Skalierung aber auch einen organisatorischen Rahmen benötigt, gewannen mit der Data Lakehouse Ära verschiedene Skalierungskonzepte an Bedeutung. Hier seien Data Fabric oder Data Mesh erwähnt. Beide Konzepte nutzen Datenprodukte zur Strukturierung der Daten und Organisation von Verantwortung.
Was genau ist ein Datenprodukt? Mit einem Datenprodukt werden die eigentlichen Daten zu einem Angebot gebündelt, dass auch eine definierte Datenqualität, fachliche Beschreibung und allgemeine Interoperabilität mit anderen Datenprodukten umfasst. Hierbei wirkt sich der Produktcharakter analog zu physischen Datenprodukten auch auf das Management von Datenprodukten aus. Es gibt also einen definierten Prozess sowie Verantwortlichkeiten für die Erstellung, Qualitätssicherung, Pflege und Weiterentwicklung des Datensatzes, der sich an den Anforderungen der Nutzer oder „Kunden“ des Datenproduktes orientiert.
“Nutzen erzeugen” heißt in diesem Fall: Der Kreis der Anwender ist bekannt und durch die zielgerichtete Nutzung des Datenproduktes wird Mehrwert generiert, der sich aus fachlichen Herausforderungen oder Use-Cases von Anwendern ergibt.
Neben den reinen Nutzdaten ist ein Datenprodukt um Metadaten ergänzt, die sowohl seine Inhalte beschreiben, als auch Kontextinformationen zur Nutzung des Datenprodukts bereitstellen.
Ein Datenprodukt ist kein Softwareprodukt, das auf Daten basiert (hier spricht man von einem datenbasierten Produkt). Es ist kein Report oder eine Visualisierung von Daten. Ein Datenprodukt ist auch nicht an eine bestimmte Technologie gebunden.“
Es ist sinnvoll neben den Datenprodukten auch die Datenapplikationen zu betrachten. Das sind dann die Softwareprodukte, welche die Datenprodukte nutzen. Datenapplikationen können Dashboards, Reports, Prognosemodelle oder KI Applikationen sein. Die Unterscheidung zwischen Datenprodukt und Datenapplikation ist für die Governance relevant.
Erkennt ein Unternehmen den Wert, der in den täglich produzierten Daten steckt, so erhebt sich natürlich der Wunsch, die Daten möglichst gewinnbringend einzusetzen. Ziel der Verantwortlichen für Datenprodukte bzw. Data Owner ist es, nicht mehr nur im eigenen Bereich möglichst viel Wertschöpfung aus den Daten zu generieren, sondern dies auch den anderen Unternehmensbereichen zu ermöglichen. Dazu sollten die verfügbaren Daten so zur Verfügung gestellt werden, dass die Nutzung durch die Prozesse und Konsumenten anderer Domänen optimal zu unterstützt wird. Die Datenbereitstellung in Data Lakehouse Systemen folgt hierbei einem marktwirtschaftlichen Gedanken, in dem verarbeitete Daten dem Unternehmen als produziertes Gut angeboten werden. Daten werden zu Datenprodukten, welche auf Angebot und Nachfrage reagieren. So bekommt Data Management zunehmend einen Lifecyle Management Aspekt und für Unternehmen werden hierdurch unterschiedliche Reifegrade von Data Analytics sichtbar.
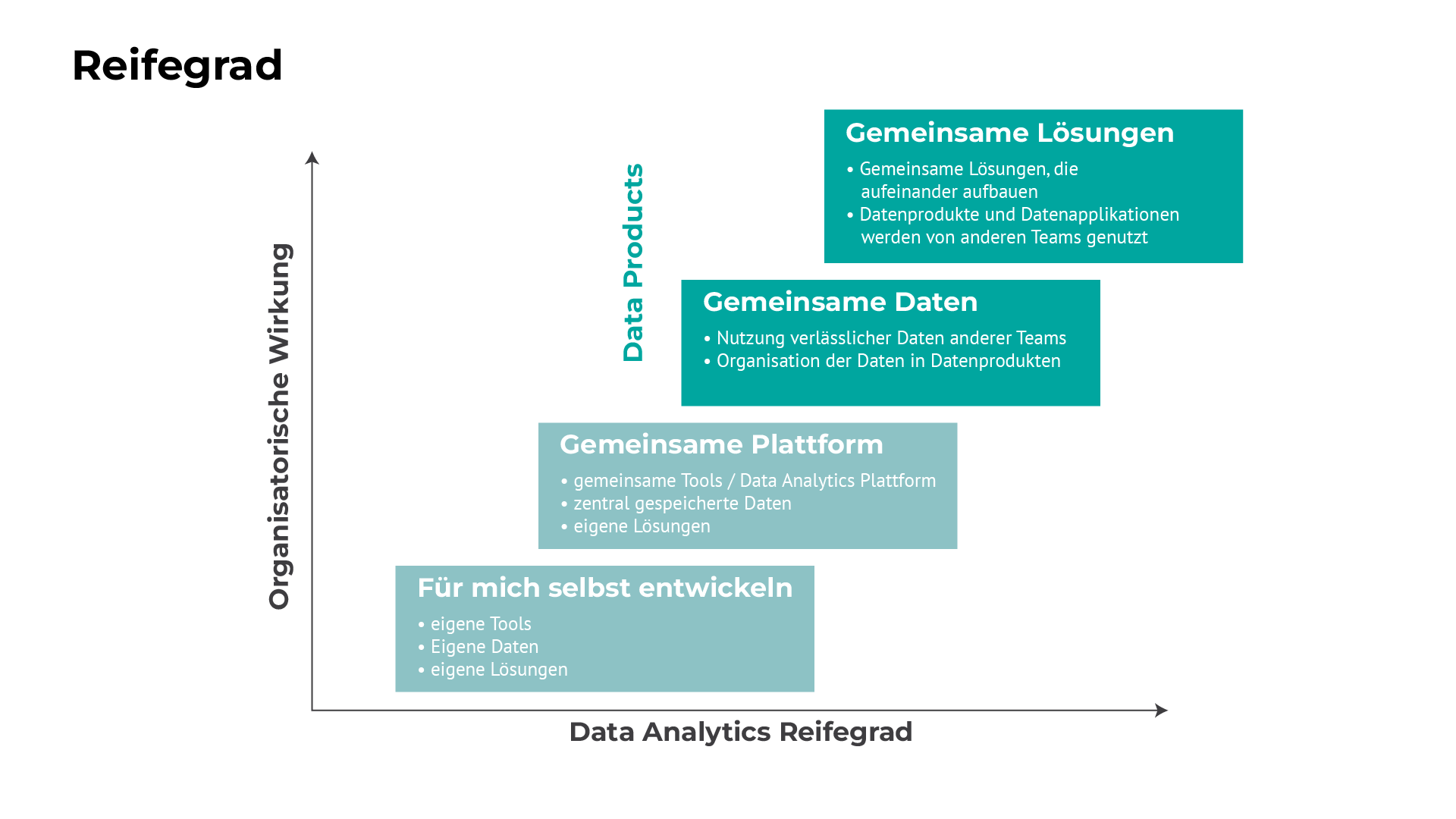
Bild: Data Analytics Reifegrade mit der Nutzung von Datenprodukten
Die Reifegerade eines datengetriebenen Unternehmens lassen sich in vier Stufen einteilen:
-
In der ersten Stufe entwickeln Teams Data Analytics Lösungen für sich selbst. Sie nutzen eigene Werkzeuge, binden die erforderlichen Datenquellen selbst an und nutzen die Lösungen auch nur im engen Umfeld des Teams.
-
In der zweiten Stufe steht eine gemeinsame Datenplattform zur Datenhaltung mit entsprechenden Werkzeugen für die Datenakquise, zur Datenauswertung und für KI Lösungen zur Verfügung. Daten werden zentral gespeichert, verschiedene Bereiche entwickeln eigene Lösungen auf dieser Plattform. Die Nutzung erfolgt im Umfeld der jeweiligen Teams.
-
In der dritten Stufe nutzen Unternehmen zur Datenorganisation Datenprodukte und oft auch Datendomänen. Durch Datenprodukte werden Daten verlässlich auch anderen Teams zur Verfügung gestellt. So können diese Datenprodukte für verschiedene Lösungen eingesetzt werden.
-
In der vierten Stufe werden Datenprodukte und Datenapplikationen im Wesentlichen für andere Nutzer erstellt und die Produktverantwortung im Unternehmen verteilt. Abgeleitete Datenprodukte bauen auf Datenprodukten anderer Teams auf. Applikationen verwenden Datenprodukte verschiedener Teams. Diese oft föderal organisierte Zusammenarbeit ermöglicht eine echte Skalierung und schafft i.d.R. die größte Wirkung für die Organisation.
Bereit für die Zukunft
Die Evolution von Datenplattformen zeigt eine kontinuierliche Anpassung an die sich wandelnden Anforderungen von Unternehmen im Laufe der Jahrzehnte. Mit Data Lakehouse Systemen sind Organisationen nun besser in der Lage, den immer komplexeren und vielfältigeren Datenanforderungen gerecht zu werden und sind für zukünftige Entwicklungen und Herausforderungen in der Datenlandschaft gut gerüstet.
„Nicht jedes Problem ist ein Nagel“
Sowohl Data Warehouse Systeme und Data Lakes sowie natürlich Data Lakehouse Systeme haben heute eine Daseinsberechtigung. Die Rahmenbedingungen und Anforderungen entscheiden über die Art der Datenplattform.
Das Data Warehouse wird genutzt, wenn strukturierte Daten aus verschiedenen Datenquellen zu integrieren sind. Data Lakes sind kostengünstige Datenspeicher für strukturierte und unstrukturierte Daten. Und Data Lakehouse Systeme kombinieren die Funktionen von Data Lake und Data Warehouse.
Die in den folgenden Abschnitten beschriebenen Prinzipien der Automation sind weitgehend auch auf Data Warehouse Systeme und Data Lakes anwendbar.
Haben Sie Fragen oder Anmerkungen? Gerne steht Ihnen unser Kollege Dr. Hendrik Weber für einen Austauch zu Verfügung. Hier geht es zu unserem Kontaktformular.